MEAL V2: Boosting Vanilla ResNet-50 to 80%+ Top-1 Accuracy on ImageNet without Tricks
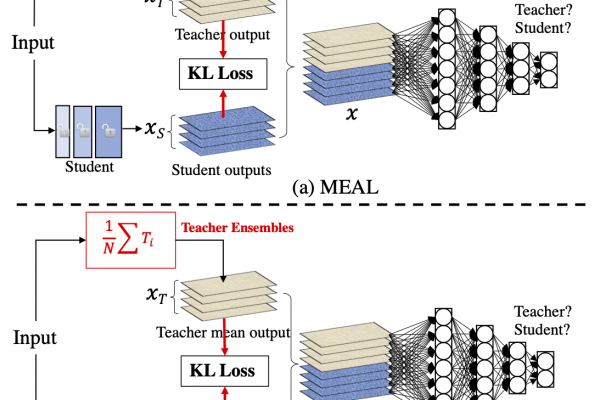
In this paper, we introduce a simple yet effective approach that can boost the vanilla ResNet-50 to 80%+ Top-1 accuracy on ImageNet without any tricks. Generally, our method is based on the recently proposed MEAL, i.e., ensemble knowledge distillation via discriminators...
We further simplify it through 1) adopting the similarity loss and discriminator only on the final outputs and 2) using the average of softmax probabilities from all teacher ensembles as the stronger supervision for distillation. One crucial perspective of our method is that the one-hot/hard label should not be used in the distillation process. We show that such a simple framework can achieve state-of-the-art results without involving any commonly-used techniques, such as 1) architecture modification; 2) outside training data beyond ImageNet; 3) autoaug/randaug; 4) cosine learning rate; 5) mixup/cutmix training; 6) label smoothing; etc. On ImageNet, our method obtains 80.67% top-1 accuracy using a single crop-size of 224X224 on the vanilla ResNet-50, outperforming the previous state-of-the-arts by a remarkable margin under the same network structure. Our result can be regarded as a new strong baseline on ResNet-50 using knowledge distillation. To our best knowledge, this is the first work that is able to boost vanilla ResNet-50 to surpass 80% on ImageNet without architecture modification or additional training data. Our code and models are available at: https://github.com/szq0214/MEAL-V2.