Learning Efficient GANs via Differentiable Masks and co-Attention Distillation
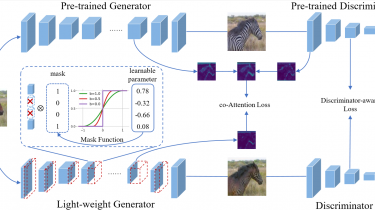
Generative Adversarial Networks (GANs) have been widely-used in image translation, but their high computational and storage costs impede the deployment on mobile devices. Prevalent methods for CNN compression cannot be directly applied to GANs due to the complicated generator architecture and the unstable adversarial training...
To solve these, in this paper, we introduce a novel GAN compression method, termed DMAD, by proposing a Differentiable Mask and a co-Attention Distillation. The former searches for a light-weight generator architecture in a training-adaptive manner. To overcome channel inconsistency when pruning the residual connections, an adaptive cross-block group sparsity is