ipython-based environment for conducting data-driven research in a consistent and reproducible way



REP is ipython-based environment for conducting data-driven research in a consistent and reproducible way.
Main features:
- unified python wrapper for different ML libraries (wrappers follow extended scikit-learn interface)
- Sklearn
- TMVA
- XGBoost
- uBoost
- Theanets
- Pybrain
- Neurolab
- MatrixNet service(available to CERN)
- parallel training of classifiers on cluster
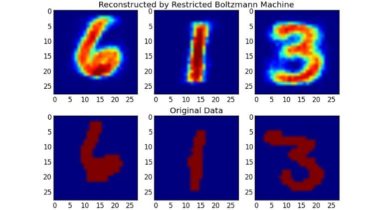
- classification/regression reports with plots
- interactive plots supported
- smart grid-search algorithms with parallel execution
- research versioning using git
- pluggable quality metrics for classification
- meta-algorithm design (aka ‘rep-lego’)
REP is not trying to substitute scikit-learn, but extends it and provides better user experience.