Improving Convolutional Neural Networks for Automatic Speech Recognition with Global Context
ContextNet
ContextNet has CNN-RNN-transducer architecture and features a fully convolutional encoder that incorporates global context information into convolution layers by adding squeeze-and-excitation modules.
Also, ContextNet supports three size models: small, medium, and large. ContextNet uses the global parameter alpha to control the scaling of the model by changing the number of channels in the convolution filter.
This repository contains only model code, but you can train with ContextNet at openspeech.
Model Architecuture
- Configuration of the ContextNet encoder
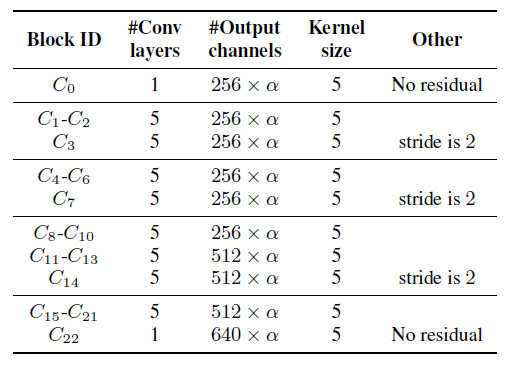
If you choose the model size among small, medium, and large, the number of channels in the convolution filter is set using the global parameter alpha. If the stride of a convolution block is 2, its last conv layer has a stride of two while the rest of