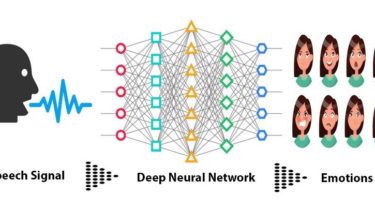
Identify the emotion of multiple speakers in an Audio Segment
MevonAI-Speech-Emotion-Recognition
Identify the emotion of multiple speakers in a Audio Segment
Getting Started
Follow the Below Instructions for setting the project up on your local Machine.
Installation
- Create a python virtual environment
sudo apt install python3-venv
mkdir mevonAI
cd mevonAI
python3 -m venv mevon-env
source mevon-env/bin/activate
- Clone the repo
git clone https://github.com/SuyashMore/MevonAI-Speech-Emotion-Recognition.git
- Install Dependencies
cd MevonAI-Speech-Emotion-Recognition/
cd src/
sudo chmod +x setup.sh
./setup.sh
Running the Application
-
Add audio files in .wav format for analysis in src/input/ folder
-
Run Speech Emotion Recognition using
python3 speechEmotionRecognition.py
-
By Default , the application will use the Pretrained Model Available in “src/model/”
-
Diarized files