How to Selectively Scale Numerical Input Variables for Machine Learning
Last Updated on August 17, 2020
Many machine learning models perform better when input variables are carefully transformed or scaled prior to modeling.
It is convenient, and therefore common, to apply the same data transforms, such as standardization and normalization, equally to all input variables. This can achieve good results on many problems. Nevertheless, better results may be achieved by carefully selecting which data transform to apply to each input variable prior to modeling.
In this tutorial, you will discover how to apply selective scaling of numerical input variables.
After completing this tutorial, you will know:
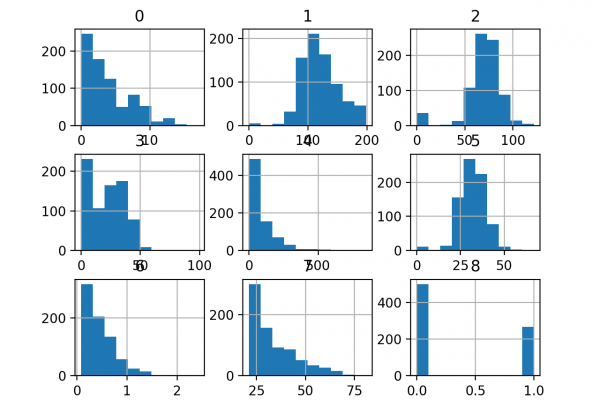
- How to load and calculate a baseline predictive performance for the diabetes classification dataset.
- How to evaluate modeling pipelines with data transforms applied blindly to all numerical input variables.
- How to evaluate modeling pipelines with selective normalization and standardization applied to subsets of input variables.
Kick-start your project with my new book Data Preparation for Machine Learning, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
 To finish reading, please visit source site
To finish reading, please visit source site