How to Develop Word Embeddings in Python with Gensim
Last Updated on September 3, 2020
Word embeddings are a modern approach for representing text in natural language processing.
Word embedding algorithms like word2vec and GloVe are key to the state-of-the-art results achieved by neural network models on natural language processing problems like machine translation.
In this tutorial, you will discover how to train and load word embedding models for natural language processing applications in Python using Gensim.
After completing this tutorial, you will know:
- How to train your own word2vec word embedding model on text data.
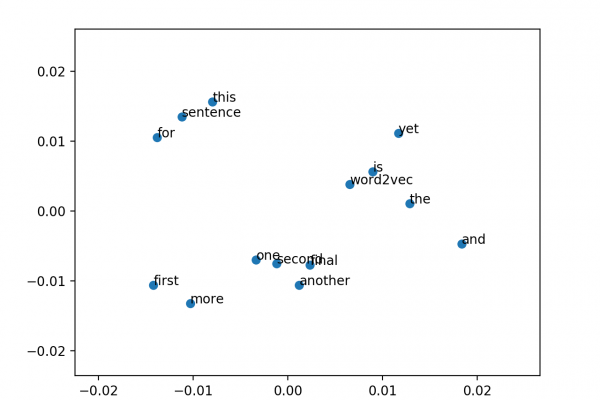
- How to visualize a trained word embedding model using Principal Component Analysis.
- How to load pre-trained word2vec and GloVe word embedding models from Google and Stanford.
Kick-start your project with my new book Deep Learning for Natural Language Processing, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.

How to Develop Word Embeddings in Python with Gensim
Photo by dilettantiquity, some rights reserved.
Tutorial Overview
This tutorial is divided into 6 parts; they
To finish reading, please visit source site