How Does Attention Work in Encoder-Decoder Recurrent Neural Networks
Last Updated on August 7, 2019
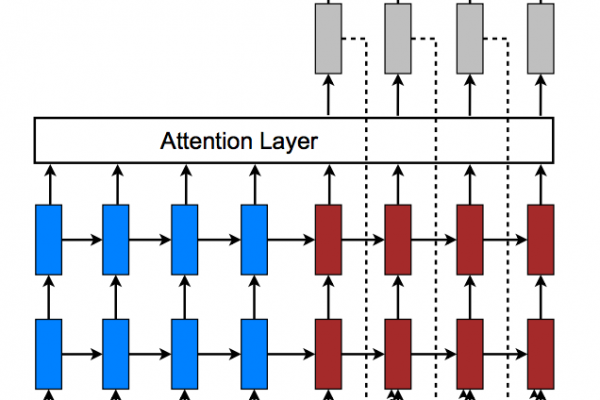
Attention is a mechanism that was developed to improve the performance of the Encoder-Decoder RNN on machine translation.
In this tutorial, you will discover the attention mechanism for the Encoder-Decoder model.
After completing this tutorial, you will know:
- About the Encoder-Decoder model and attention mechanism for machine translation.
- How to implement the attention mechanism step-by-step.
- Applications and extensions to the attention mechanism.
Kick-start your project with my new book Deep Learning for Natural Language Processing, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
- Update Dec/2017: Fixed a small typo in Step 4, thanks Cynthia Freeman.
Tutorial Overview
This tutorial is divided into 4 parts; they are:
- Encoder-Decoder Model
- Attention Model
- Worked Example of Attention
- Extensions to Attention
Encoder-Decoder Model
The Encoder-Decoder model for recurrent neural networks was introduced in two papers.
Both developed the technique to address the sequence-to-sequence nature of machine translation where input sequences differ in length from output sequences.
Ilya Sutskever, et al. do so in the paper “Sequence to Sequence Learning with Neural Networks” using LSTMs.
Kyunghyun Cho, et al. do so in the paper “Learning Phrase Representations
To finish reading, please visit source site