Fault tolerant, stealthy, distributed web crawling with Pyppeteer
crawler-cluster
Distributed, Fault-Tolerant Web Crawling.
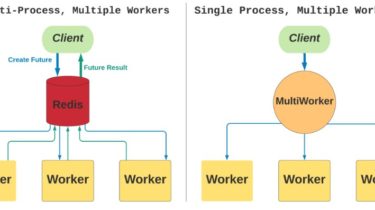
Multi-process, multiple workers
- Client process queues tasks in Redis.
- Worker nodes pull tasks from Redis, execute task, and store results in Redis.
- Client process pulls results from Redis.
Pros:
- Worker nodes can run on any machine.
- Add or remove worker nodes at runtime without disrupting the system.
- Achieves fault-tolerance through process isolation and monitoring.
- Workers are ran as systemd services, where each service is the smallest possible processing unit (either a single browser with a single page, or a single vanilla HTTP client).
Browsers with only a single page (single tab open) are less prone to crashes and there’s also no disadvantage in terms of system resource usage as running n single-page browsers simultaneously will use almost identical resources as a single browser running
- Workers are ran as systemd services, where each service is the smallest possible processing unit (either a single browser with a single page, or a single vanilla HTTP client).