DeepSpeed ZeRO++: A leap in speed for LLM and chat model training with 4X less communication
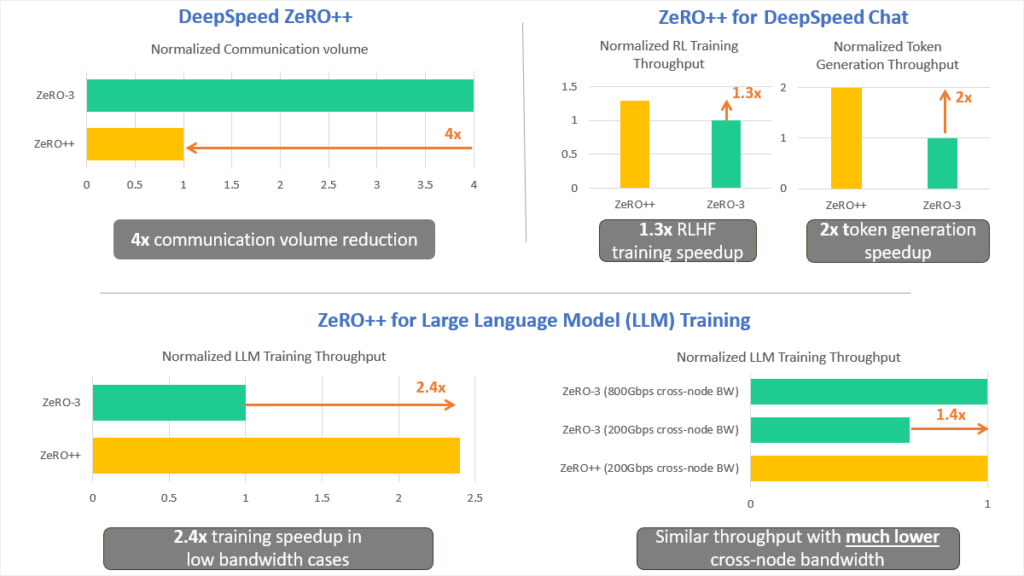
Large AI models are transforming the digital world. Generative language models like Turing-NLG, ChatGPT, and GPT-4, powered by large language models (LLMs), are incredibly versatile, capable of performing tasks like summarization, coding, and translation. Similarly, large multimodal generative models like DALL·E, Microsoft Designer,