Created covid data pipeline using PySpark and MySQL that collected data stream from API
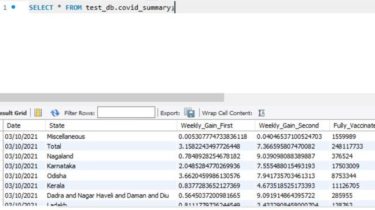
Created covid data pipeline using PySpark and MySQL that collected data stream from API and do some processing and store it into MYSQL database.
Tools used : PySpark , MySQL
Procedure
-
Fetch latest data from API using requests & pandas module of python.
-
Apply some data processing and filtering to generate summarized information.
-
Store that summarized information into database using MySQL.
To build above pipeline i had used pyspark
{IMPORTANT}
Before move to the execution part please read below sentences
-
Use correct connector and drivername while making connection with MySQL db if you are going to use