Chasing Sparsity in Vision Transformers: An End-to-End Exploration
SViTE
[Preprint] “Chasing Sparsity in Vision Transformers: An End-to-End Exploration” by Tianlong Chen, Yu Cheng, Zhe Gan, Lu Yuan, Lei Zhang, Zhangyang Wang
Extensive results on ImageNet with diverse ViT backbones validate the effectiveness of our proposals which obtain significantly reduced computational cost and almost unimpaired generalization. Perhaps most surprisingly, we find that the proposed sparse (co-)training can even improve the ViT accuracy rather than compromising it, making sparsity a tantalizing “free lunch”. For example, our sparsified DeiT-Small at (5%, 50%) sparsity for (data, architecture), improves 0.28% top-1 accuracy, and meanwhile enjoys 49.32% FLOPs and 4.40% running time savings.
Proposed Framework of SViTE
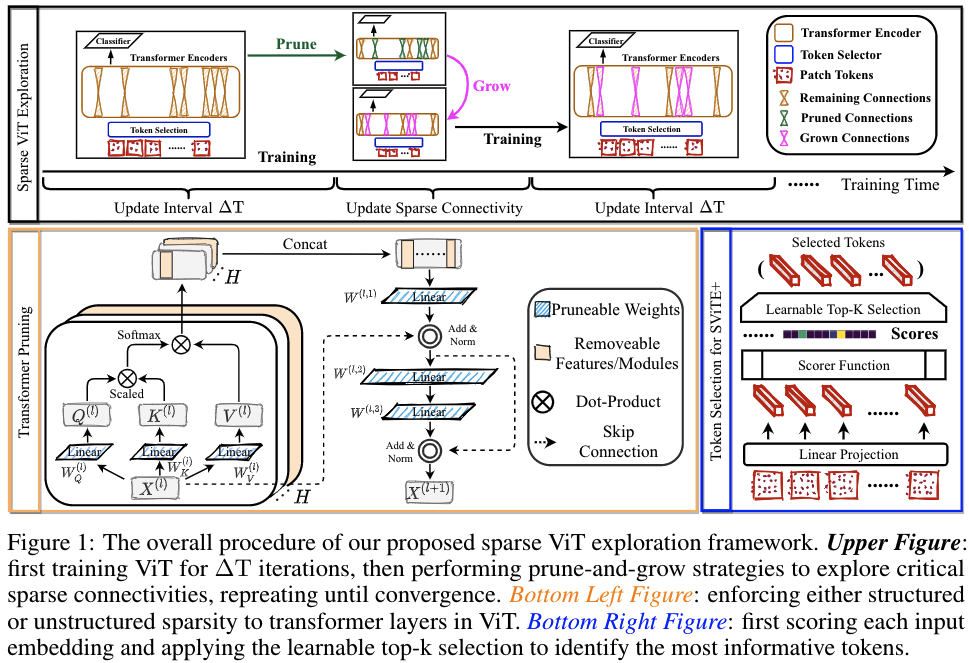
Implementations of SViTE
Set Environment
conda create -n vit python=3.6
pip install torch==1.7.1+cu101 torchvision==0.8.2+cu101 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
pip install tqdm