Beyond Masking: Demystifying Token-Based Pre-Training for Vision Transformers
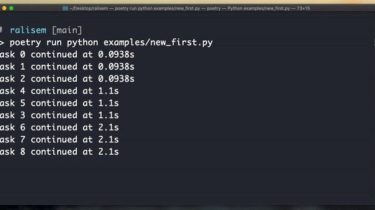
beyond masking Beyond Masking: Demystifying Token-Based Pre-Training for Vision Transformers The code is coming Figure 1: Pipeline of token-based pre-training. Figure 2: The visualization of the proposed 5 tasks. main results All the results are pre-trained for 300 epochs using Vit-base as default. zoomed-in zoomed-out distorted blurred de-colorized finetune 82.7 82.5 82.1 81.8 81.4 zoomed-in (a) mask (m) (a)+(m) finetune 82.7 82.9 83.2 We note that the integrated version dose not require
Read more