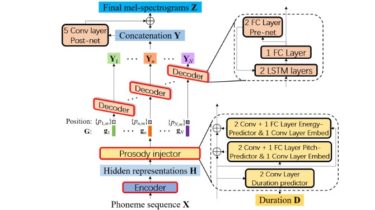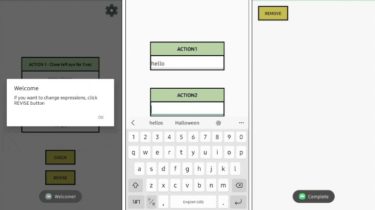
HOVI: Creates Text-to-Speech messages from people’s face movement to help people who have difficulty communicating with one’s voice
Team Member: Kang Inyeong, Kim Yeonghyeon, Lee Seulbi, Park Jisoo from GDSC SeoulTech (2021.12.21-ing) 🌱 Index What is HOVI? What is HOVI’s SDGs? Who can be a HOVI’s user? Used Technology/Diagram How to use? Demo Video What is HOVI’s Vision? Who develop HOVI? 🌱 What is HOVI? HOVI means ‘Have Own Voice Intermidiator’. The application creates Text-to-Speech messages from people’s face movement to help people who have difficulty communicating with one’s voice. HOVI is used as follows : 1️⃣ Use […]
Read more