PyTorch implementation of Advantage Actor Critic
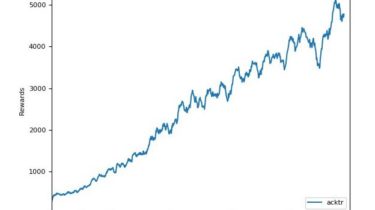
pytorch-a2c-ppo-acktr PyTorch implementation of Advantage Actor Critic (A2C), Proximal Policy Optimization (PPO), Scalable trust-region method for deep reinforcement learning using Kronecker-factored approximation (ACKTR) and Generative Adversarial Imitation Learning (GAIL). Please use hyper parameters from this readme. With other hyper parameters things might not work (it’s RL after all)! This is a PyTorch implementation of Advantage Actor Critic (A2C), a synchronous deterministic version of A3C Proximal Policy Optimization PPO Scalable trust-region method for deep reinforcement learning using Kronecker-factored approximation ACKTR Generative […]
Read more