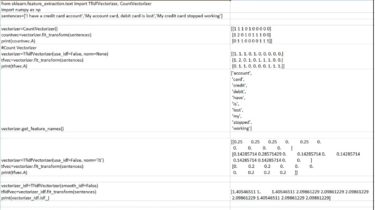
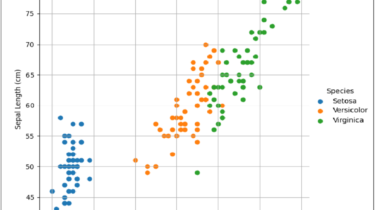
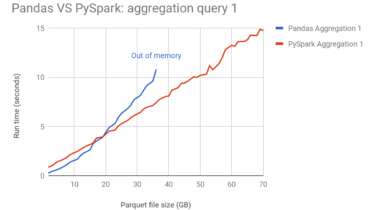
Build a Tic-Tac-Toe Game Engine With an AI Player in Python
When you’re a child, you learn to play tic-tac-toe, which some people know as naughts and crosses. The game remains fun and challenging until you enter your teenage years. Then, you learn to program and discover the joy of coding a virtual version of this two-player game. As an adult, you may still appreciate the simplicity of the game by using Python to create an opponent with artificial intelligence (AI). By completing this detailed step-by-step adventure, you’ll build an extensible […]
Read more