A Simple Introduction to Sequence to Sequence Models
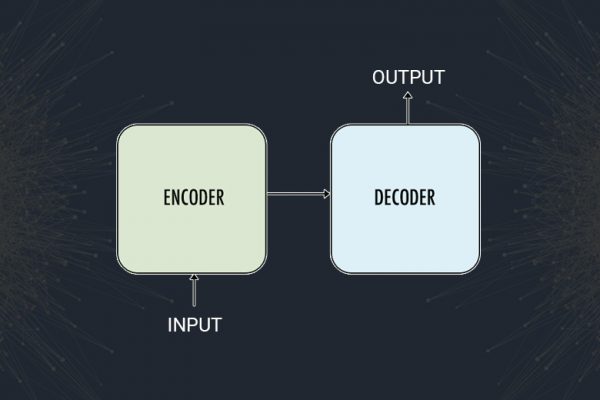
Overview In this article, I would give you an overview of sequence to sequence models which became quite popular for different tasks like machine translation, video captioning, image captioning, question answering, etc. Prerequisites: The reader should already be familiar with neural networks and, in particular, recurrent neural networks (RNNs). In addition, knowledge of LSTM or GRU models is preferable. If you are not familiar with LSTM I would prefer you to read LSTM- Long Short-Term Memory.
Read more