Improving the User Experience with Uber’s Customer Obsession Ticket Routing Workflow and Orchestration Engine
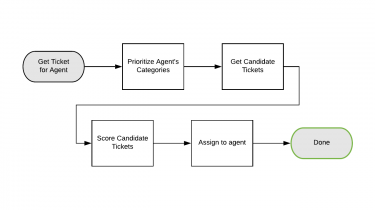
Every day, Uber users around the world initiate customer support tickets through our Customer Obsession Platform. To ensure a seamless user experience, each of those tickets must be matched with an agent who speaks the user’s language and who has been trained to handle issues of that type and in that country, among other qualifications. Routing tickets to an agent with the right skillset has become more complex as
Read more