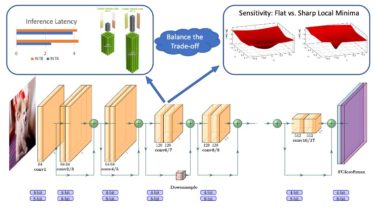
Enhancing Unsupervised Video Representation Learning
DSM The source code for paper Enhancing Unsupervised Video Representation Learning by Decoupling the Scene and the Motion 1. Introduction (scene-dominated to motion-dominated) Video datasets are usually scene-dominated, We propose to decouple the scene and the motion (DSM) with two simple operations, so that the model attention towards the motion information is better paid. The generated triplet is as below: What DSM learned? With DSM pretrain, the model learn to focus on motion region (Not necessarily actor) powerful without one […]
Read more