Text Preprocessing
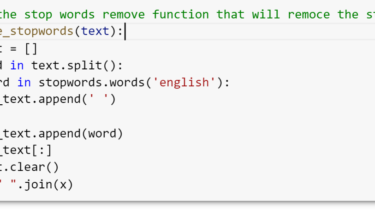
This is the second step of the NLP end-to-end pipeline. In this step, We generally perform basic preprocessing and then advanced preprocessing but it depends on problem to problem. Let’s see the steps of text preprocessing. Lowercasing:- This is the first step of data preprocessing. It’s compulsory for all kinds of problems because whenever we work on an
Read more