Random Forest for Time Series Forecasting
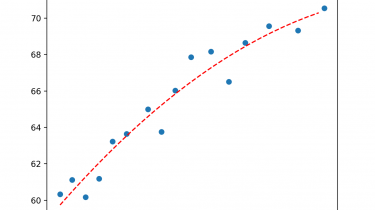
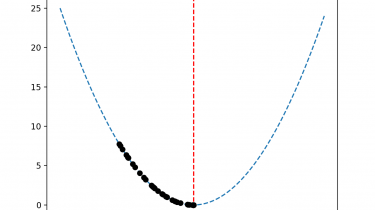
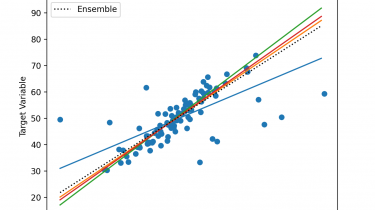
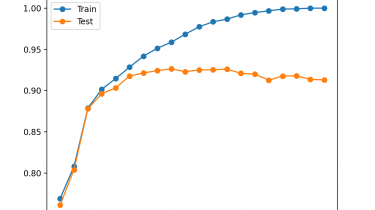
Random Forest is a popular and effective ensemble machine learning algorithm. It is widely used for classification and regression predictive modeling problems with structured (tabular) data sets, e.g. data as it looks in a spreadsheet or database table. Random Forest can also be used for time series forecasting, although it requires that the time series dataset be transformed into a supervised learning problem first. It also requires the use of a specialized technique for evaluating the model called walk-forward validation, […]
Read more