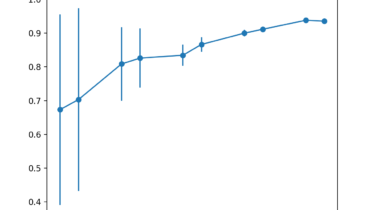
Sensitivity Analysis of Dataset Size vs. Model Performance
Machine learning model performance often improves with dataset size for predictive modeling. This depends on the specific datasets and on the choice of model, although it often means that using more data can result in better performance and that discoveries made using smaller datasets to estimate model performance often scale to using larger datasets. The problem is the relationship is unknown for a given dataset and model, and may not exist for some datasets and models. Additionally, if such a […]
Read more