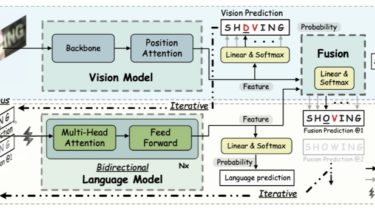
Autonomous, Bidirectional and Iterative Language Modeling for Scene Text Recognition
ABINet Read Like Humans: Autonomous, Bidirectional and Iterative Language Modeling for Scene Text Recognition The official code of ABINet (CVPR 2021, Oral). ABINet uses a vision model and an explicit language model to recognize text in the wild, which are trained in end-to-end way. The language model (BCN) achieves bidirectional language representation in simulating cloze test, additionally utilizing iterative correction strategy. Runtime Environment We provide a pre-built docker image using the Dockerfile from docker/Dockerfile Running in Docker $ [email protected]:FangShancheng/ABINet.git $ […]
Read more