End-to-End Pre-training for Vision-Language Representation Learning
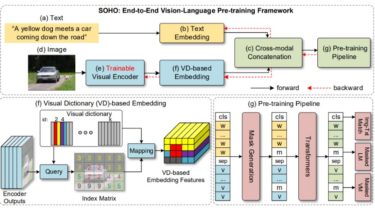
Seeing Out of tHe bOx End-to-End Pre-training for Vision-Language Representation Learning [CVPR’21, Oral]By Zhicheng Huang*, Zhaoyang Zeng*, Yupan Huang*, Bei Liu, Dongmei Fu and Jianlong Fu arxiv: https://arxiv.org/pdf/2104.03135.pdf This is the official implementation of the paper. In this paper, we propose SOHO to “See Out of tHe bOx” that takes a whole image as input, and learns vision-language representation in an end-to-end manner. SOHO does not require bounding box annotations which enables inference 10 times faster than region-based approaches. Architecture […]
Read more