Add Binary Flags for Missing Values for Machine Learning
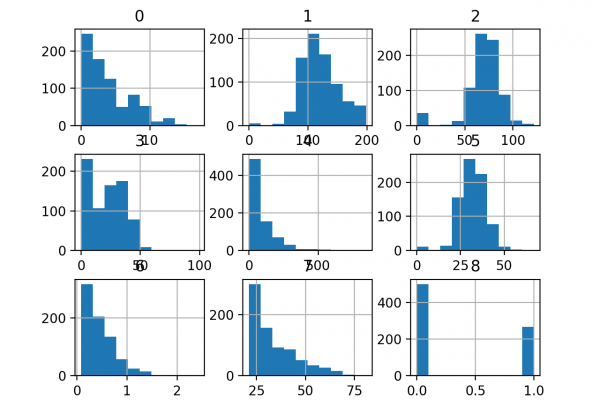
Last Updated on August 17, 2020 Missing values can cause problems when modeling classification and regression prediction problems with machine learning algorithms. A common approach is to replace missing values with a calculated statistic, such as the mean of the column. This allows the dataset to be modeled as per normal but gives no indication to the model that the row original contained missing values. One approach to address this issue is to include additional binary flag input features that […]
Read more