Develop an Intuition for Severely Skewed Class Distributions
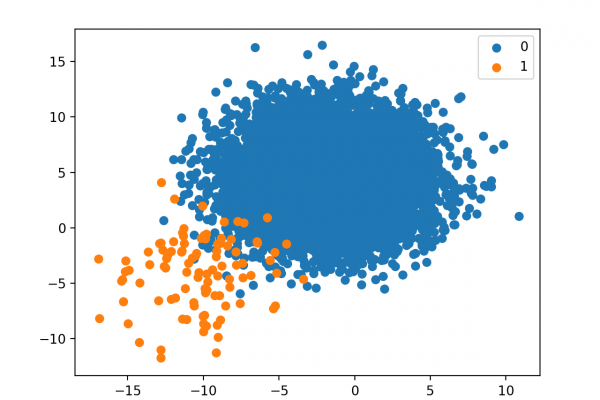
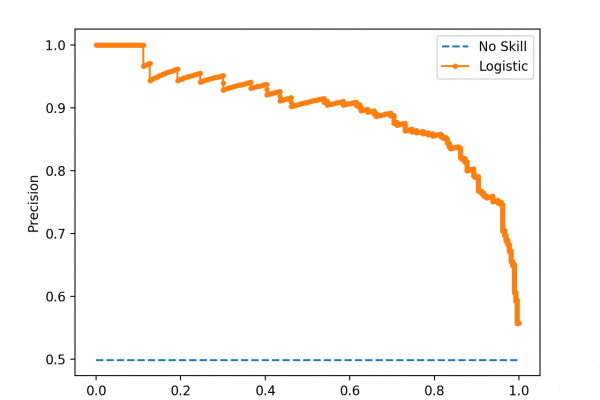
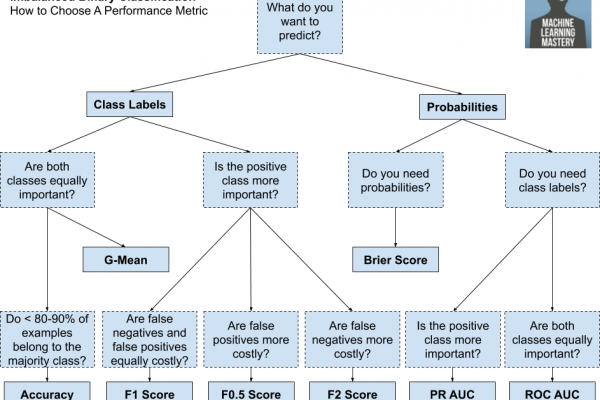
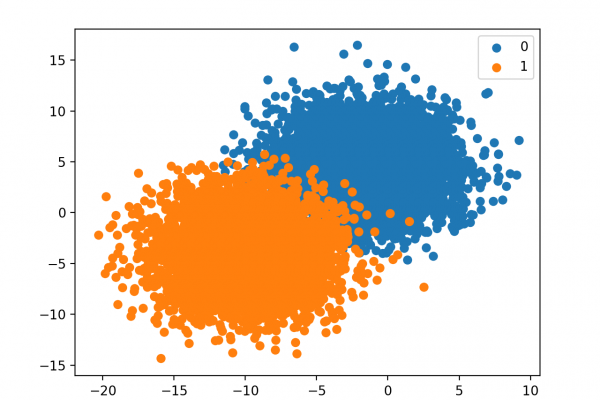
Last Updated on January 14, 2020 An imbalanced classification problem is a problem that involves predicting a class label where the distribution of class labels in the training dataset is not equal. A challenge for beginners working with imbalanced classification problems is what a specific skewed class distribution means. For example, what is the difference and implication for a 1:10 vs. a 1:100 class ratio? Differences in the class distribution for an imbalanced classification problem will influence the choice of […]
Read more