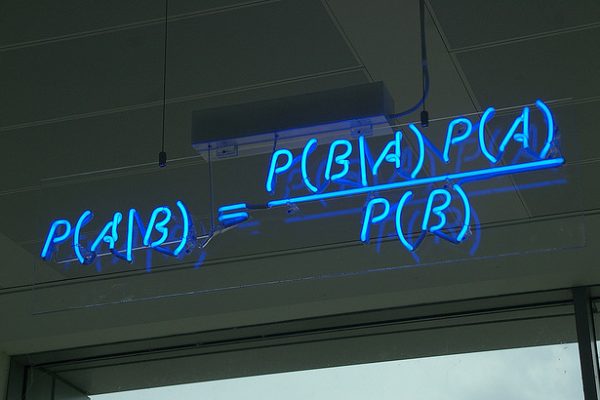A Gentle Introduction to Bayes Theorem for Machine Learning
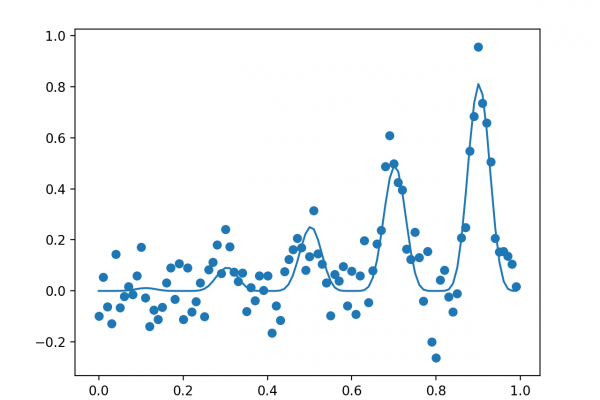
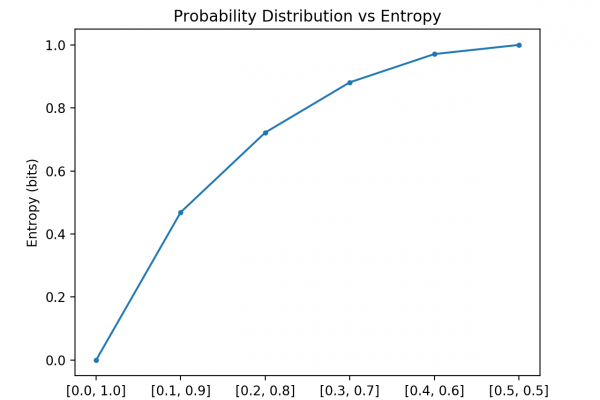
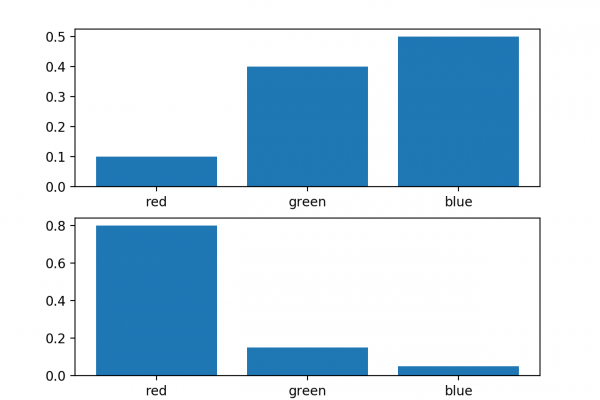
Last Updated on December 4, 2019 Bayes Theorem provides a principled way for calculating a conditional probability. It is a deceptively simple calculation, although it can be used to easily calculate the conditional probability of events where intuition often fails. Although it is a powerful tool in the field of probability, Bayes Theorem is also widely used in the field of machine learning. Including its use in a probability framework for fitting a model to a training dataset, referred to […]
Read more