Case Study: Predicting the Onset of Diabetes Within Five Years (part 2 of 3)
Last Updated on August 22, 2019
This is a guest post by Igor Shvartser, a clever young student I have been coaching.
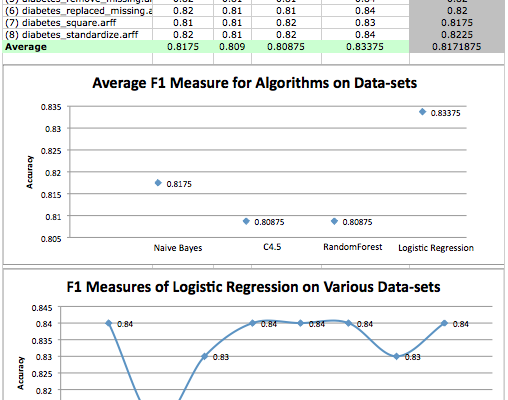
This post is part 2 in a 3 part series on modeling the famous Pima Indians Diabetes dataset (update: download from here). In Part 1 we defined the problem and looked at the dataset, describing observations from the patterns we noticed in the data.
In this we will introduce the methodology, spot checking algorithms, and review initial results.
Kick-start your project with my new book Machine Learning Mastery With Weka, including step-by-step tutorials and clear screenshots for all examples.
Methodology
Analysis and data processing in the study was carried out using the Weka machine learning software. A ten-fold cross-validation was used for experiments. This works in the following way:
- Produce 10 equal sized data sets from given data
- Divide each set into two groups: 90% for training and 10% for testing.
- Produce a classifier with
To finish reading, please visit source site