BARTScore: Evaluating Generated Text as Text Generation

BARTScore
Evaluating Generated Text as Text Generation.
Background
There is a recent trend that leverages neural models for automated evaluation in different ways, as shown in Fig.1.
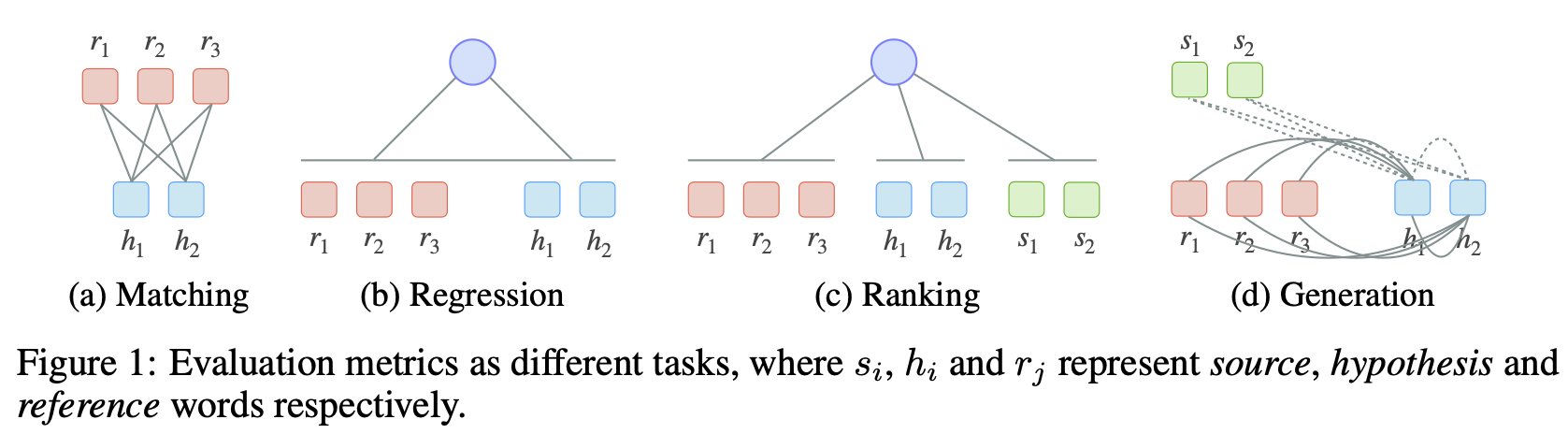
(a) Evaluation as matching task. Unsupervised matching metrics aim to measure the semantic equivalence between the reference and hypothesis by using a token-level matching functions in distributed representation space (e.g. BERT) or discrete string space (e.g. ROUGE).
(b) Evaluation as regression task. Regression-based metrics (e.g. BLEURT) introduce a parameterized regression layer, which would be learned in a supervised fashion to accurately predict human judgments.
(c) Evaluation as ranking task. Ranking-based metrics (e.g. COMET) aim to learn a scoring function that assigns a higher score to better hypotheses than to worse ones.
(d) Evaluation as generation