AWS Data Engineering Pipeline with python
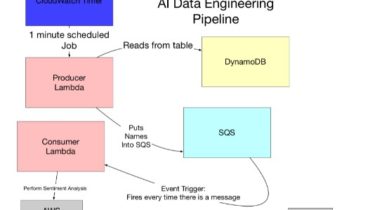
AWS Data Engineering Pipeline
This is a repository for the Duke University Cloud Computing course project on Serverless Data Engineering Pipeline. For this project, I recreated the below pipeline in iCloud9 (reference: https://github.com/noahgift/awslambda):
Below are the steps of how to build this pipeline in AWS:
1️⃣ Create a new iCloud9 environment dedicated to this project.
🤔 Need a refresher? Please check this repo.
⚠️ Make sure to use name as your unique id for your items in the fang table.
2️⃣ Create a fang table in DynamoDB and SQS queue.
You can check how to do it here.
3️⃣ Build producer Lambda Function
-
In iCloud9, initialize a serverless application with SAM template:
sam init
Inputs: 1, 2, 4, “producer”