Automatic Audio-to-symbolic Arrangement
This is the repository of the project “Audio-to-symbolic Arrangement via Cross-modal Music Representation Learning” by Ziyu Wang, Dejing Xu, Gus Xia and Ying Shan (arXiv:2112.15110).
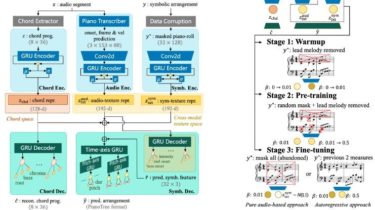
Model Overview
We propose an audio-to-symbolic generative model to transfer an input audio to its piano arrangement (in MIDI format). The task is similar to piano cover song production based on the original pop songs, or piano score reduction based on a classical symphony.
The input audio is a pop-song audio under arbitrary instrumentation. The output is a MIDI piano arrangement of the original audio which keeps most musical information (incdluding chord, groove and lead melody). The model is built upon the previous projects including EC2-VAE, PianoTree VAE, and Poly-Dis. The novelty of this study is