A torch implementation of a recursion which turns out to be useful for RNN-T
This project implements a method for faster and more memory-efficient RNN-T loss computation, called pruned rnnt.
Note: There is also a fast RNN-T loss implementation in k2 project, which shares the same code here. We make fast_rnnt a stand-alone project in case someone wants only this rnnt loss.
How does the pruned-rnnt work ?
We first obtain pruning bounds for the RNN-T recursion using a simple joiner network that is just an addition of the encoder and decoder, then we use those pruning bounds to evaluate the full, non-linear joiner network.
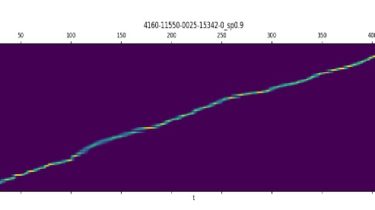
The picture below display the gradients (obtained by rnnt_loss_simple with return_grad=true) of lattice nodes, at each time frame, only a small set of nodes have a non-zero gradient, which justifies the pruned RNN-T loss, i.e., putting a