A pytorch reprelication of the model-based reinforcement learning algorithm MBPO
mbpo_pytorch
This is a re-implementation of the model-based RL algorithm MBPO in pytorch as described in the following paper: When to Trust Your Model: Model-Based Policy Optimization.
This code is based on a previous paper in the NeurIPS reproducibility challenge that reproduces the result with a tensorflow ensemble model but shows a significant drop in performance with a pytorch ensemble model. This code re-implements the ensemble dynamics model with pytorch and closes the gap.
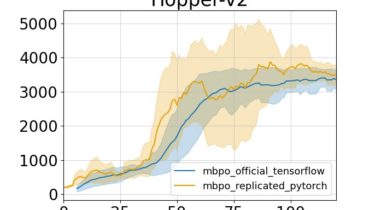
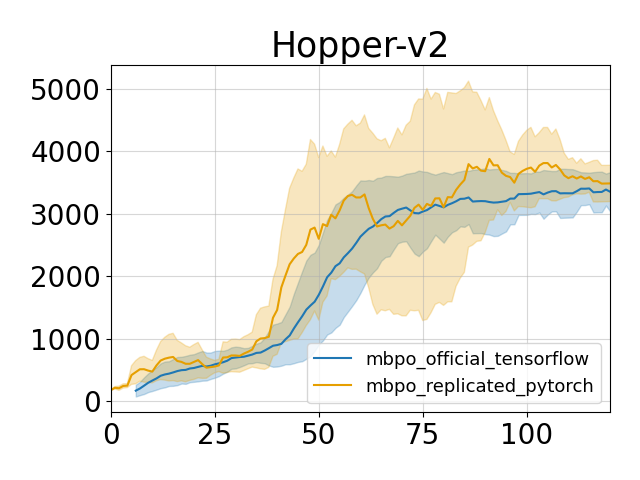
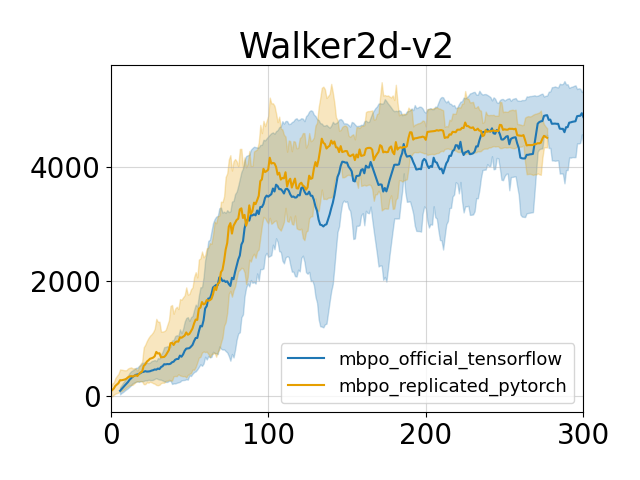
Reproduced results
The comparison are done on two tasks while other tasks are not tested. But on the tested two tasks, the pytorch implementation achieves similar performance compared to the official tensorflow code.
Dependencies
MuJoCo 1.5 & MuJoCo 2.0
Usage
python