A Gentle Introduction to the Rectified Linear Unit (ReLU)
Last Updated on August 20, 2020
In a neural network, the activation function is responsible for transforming the summed weighted input from the node into the activation of the node or output for that input.
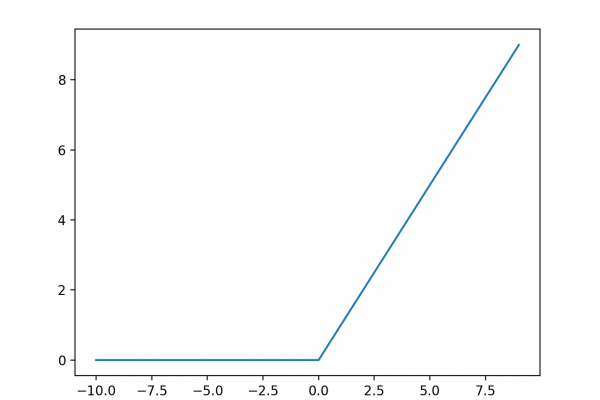
The rectified linear activation function or ReLU for short is a piecewise linear function that will output the input directly if it is positive, otherwise, it will output zero. It has become the default activation function for many types of neural networks because a model that uses it is easier to train and often achieves better performance.
In this tutorial, you will discover the rectified linear activation function for deep learning neural networks.
After completing this tutorial, you will know:
- The sigmoid and hyperbolic tangent activation functions cannot be used in networks with many layers due to the vanishing gradient problem.
- The rectified linear activation function overcomes the vanishing gradient problem, allowing models to learn faster and perform better.
- The rectified linear activation is the default activation when developing multilayer Perceptron and convolutional neural networks.
Kick-start your project with my new book Better Deep Learning, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
- Jun/2019: Fixed
To finish reading, please visit source site