K-Means Clustering with Scikit-Learn

Introduction
K-means clustering is one of the most widely used unsupervised machine learning algorithms that forms clusters of data based on the similarity between data instances. For this particular algorithm to work, the number of clusters has to be defined beforehand. The K in the K-means refers to the number of clusters.
The K-means algorithm starts by randomly choosing a centroid value for each cluster. After that the algorithm iteratively performs three steps: (i) Find the Euclidean distance between each data instance and centroids of all the clusters; (ii) Assign the data instances to the cluster of the centroid with nearest distance; (iii) Calculate new centroid values based on the mean values of the coordinates of all the data instances from the corresponding cluster.
A Simple Example
Let’s try to see how the K-means algorithm works with the help of a handcrafted example, before implementing the algorithm in Scikit-Learn. It takes three lines of code to implement the K-means clustering algorithm in Scikit-Learn. However, to understand how it actually works, let’s first solve a clustering problem using K-means clustering “on paper”.
Suppose we have a set of the following two dimensional data instances named D.
D = { (5,3), (10,15), (15,12), (24,10), (30,45), (85,70), (71,80), (60,78), (55,52), (80,91) }
We want to divide this data into two clusters, C1 and C2 based on the similarity between the data points.
The first step is to randomly initialize values for the centroids of both clusters. Let’s name centroids of clusters C1 and C2 as c1 and c2 and initialize them with the values of the first two data points i.e. (5, 3) and (10, 15).
Now we have to start the iterations.
Iteration 1
| S.No | Data Points | Euclidean Distance from Cluster Centroid c1 = (5,3) | Euclidean Distance from Cluster Centroid c2 = (10,15) | Assigned Cluster |
|---|---|---|---|---|
| 1 | (5,3) | 0 | 13 | C1 |
| 2 | (10,15) | 13 | 0 | C2 |
| 3 | (15,12) | 13.45 | 5.83 | C2 |
| 4 | (24,10) | 20.24 | 14.86 | C2 |
| 5 | (30,45) | 48.87 | 36 | C2 |
| 6 | (85,70) | 104.35 | 93 | C2 |
| 7 | (71,80) | 101.41 | 89 | C2 |
| 8 | (60,78) | 93 | 80 | C2 |
| 9 | (55,52) | 70 | 58 | C2 |
| 10 | (80,91) | 115.52 | 103.32 | C2 |
In the table above, the second column contains all the data points. The third column contains the Euclidean distance between all the data points and centroid c1. Similarly the fourth column contains distance between the c2 centroid and the data points. Finally, in the fifth column we show which cluster the data point is assigned to based on the Euclidean distance between the two cluster centroids. For instance, look at the third data point (15, 12). It has a distance of 13.45 units from c1 while a distance of 5.83 units from c2; therefore it has been clustered in C2.
After assigning data points to the corresponding clusters, the next step is to calculate the new centroid values. These values are calculated by finding the means of the coordinates of the data points that belong to a particular cluster.
For cluster C1, there is currently only one point i.e. (5,3), therefore the mean of the coordinates remain same and the new centroid value for c1 will also be (5,3).
For C2, there are currently 9 data points. We name the coordinates of data points as x and y. The new value for x coordinate of centroid c2 can be calculated by determining the mean of x coordinates of all 9 points that belong to cluster C2 as given below:
c2(x) = (10 + 15 + 24 + 30 + 85 + 71 + 60 + 55 + 80) / 9 = 47.77
The new value for y coordinate of centroid c2 can be calculated by determining the mean of all y coordinates of all 9 points that belong to cluster C2.
c2(y) = (15 + 12 + 10 + 45 + 70 + 80 + 78 + 52 + 91) / 9 = 50.33
The updated centroid value for c2 will now be {47.77, 50.33}.
For the next iteration, the new centroid values for c1 and c2 will be used and the whole process will be repeated. The iterations continue until the centroid values stop updating. The next iterations are as follows:
Iteration 2
| S.No | Data Points | Euclidean Distance from Cluster Centroid c1 = (5,3) | Euclidean Distance from Cluster Centroid c2 = (47.77,50.33) | Assigned Cluster |
|---|---|---|---|---|
| 1 | (5,3) | 0 | 63.79 | C1 |
| 2 | (10,15) | 13 | 51.71 | C1 |
| 3 | (15,12) | 13.45 | 50.42 | C1 |
| 4 | (24,10) | 20.24 | 46.81 | C1 |
| 5 | (30,45) | 48.87 | 18.55 | C2 |
| 6 | (85,70) | 104.35 | 42.10 | C2 |
| 7 | (71,80) | 101.41 | 37.68 | C2 |
| 8 | (60,78) | 93 | 30.25 | C2 |
| 9 | (55,52) | 70 | 7.42 | C2 |
| 10 | (80,91) | 115.52 | 51.89 | C2 |
c1(x) = (5, 10, 15, 24) / 4 = 13.5
c1(y) = (3, 15, 12, 10) / 4 = 10.0
Updated c1 to be (13.5, 10.0).
c2(x) = (30 + 85 + 71 + 60 + 55 + 80) / 6 = 63.5
c2(y) = (45 + 70 + 80 + 78 + 52 +91) / 6 = 69.33
Updated c2 to be (63.5, 69.33).
Iteration 3
| S.No | Data Points | Euclidean Distance from Cluster Centroid c1= (13.5,10) | Euclidean Distance from Cluster Centroid c2= (63.5,69.33) | Assigned Cluster |
|---|---|---|---|---|
| 1 | (5,3) | 11.01 | 88.44 | C1 |
| 2 | (10,15) | 6.10 | 76.24 | C1 |
| 3 | (15,12) | 2.5 | 75.09 | C1 |
| 4 | (24,10) | 10.5 | 71.27 | C1 |
| 5 | (30,45) | 38.69 | 41.40 | C1 |
| 6 | (85,70) | 93.33 | 21.51 | C2 |
| 7 | (71,80) | 90.58 | 13.04 | C2 |
| 8 | (60,78) | 82.37 | 9.34 | C2 |
| 9 | (55,52) | 59.04 | 19.30 | C2 |
| 10 | (80,91) | 104.80 | 27.23 | C2 |
c1(x) = (5, 10, 15, 24, 30) / 5 = 16.8
c1(y) = (3, 15, 12, 10, 45) / 5 = 17.0
Updated c1 to be (16.8, 17.0).
c2(x) = (85 + 71 + 60 + 55 + 80) / 5 = 70.2
c2(y) = (70 + 80 + 78 + 52 + 91) / 5 = 74.2
Updated c2 to be (70.2, 74.2).
Iteration 4
| S.No | Data Points | Euclidean Distance from Cluster Centroid c1 = (16.8,17) | Euclidean Distance from Cluster Centroid c2 = (70.2,74.2) | Assigned Cluster |
|---|---|---|---|---|
| 1 | (5,3) | 18.30 | 96.54 | C1 |
| 2 | (10,15) | 7.08 | 84.43 | C1 |
| 3 | (15,12) | 5.31 | 83.16 | C1 |
| 4 | (24,10) | 10.04 | 79.09 | C1 |
| 5 | (30,45) | 30.95 | 49.68 | C1 |
| 6 | (85,70) | 86.37 | 15.38 | C2 |
| 7 | (71,80) | 83.10 | 5.85 | C2 |
| 8 | (60,78) | 74.74 | 10.88 | C2 |
| 9 | (55,52) | 51.80 | 26.90 | C2 |
| 10 | (80,91) | 97.31 | 19.44 | C2 |
c1(x) = (5, 10, 15, 24, 30) / 5 = 16.8
c1(y) = (3, 15, 12, 10, 45) / 5 = 17.0
Updated c1 to be (16.8, 17.0).
c2(x) = (85 + 71 + 60 + 55 + 80) / 5 = 70.2
c2(y) = (70 + 80 + 78 + 52 + 91) / 5 = 74.2
Updated c2 to be (70.2, 74.2).
At the end of fourth iteration, the updated values of C1 and C2 are same as they were at the end of the third iteration. This means that data cannot be clustered any further. c1 and c2 are the centroids for C1 and C2. To classify a new data point, the distance between the data point and the centroids of the clusters is calculated. Data point is assigned to the cluster whose centroid is closest to the data point.
K-means Clustering with Scikit-Learn
Now that we know how the K-means clustering algorithm actually works, let’s see how we can implement it with Scikit-Learn.
To run the following script you need the matplotlib, numpy, and scikit-learn libraries. Check the following links for instructions on how to download and install these libraries.
Import Libraries
Let’s start our script by first importing the required libraries:
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
from sklearn.cluster import KMeans
Prepare Data
The next step is to prepare the data that we want to cluster. Let’s create a numpy array of 10 rows and 2 columns. The row contains the same data points that we used for our manual K-means clustering example in the last section. We create a numpy array of data points because the Scikit-Learn library can work with numpy array type data inputs without requiring any preprocessing.
X = np.array([[5,3],
[10,15],
[15,12],
[24,10],
[30,45],
[85,70],
[71,80],
[60,78],
[55,52],
[80,91],])
Visualize the Data
You can see these are the same data points that we used in the previous example. Let’s plot these points and check if we can eyeball any clusters. To do so, execute the following line:
plt.scatter(X[:,0],X[:,1], label='True Position')
The above code simply plots all the values in the first column of the X array against all the values in the second column. The graph will look like this:
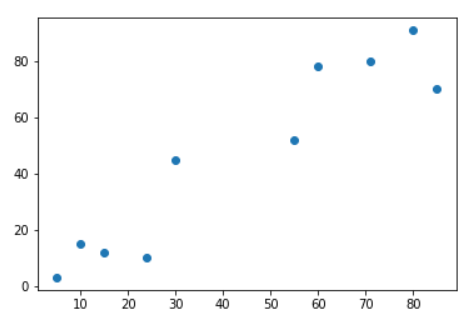
From the naked eye, if we have to form two clusters of the above data points, we will probably make one cluster of five points on the bottom left and one cluster of five points on the top right. Let’s see if our K-means clustering algorithm does the same or not.
Create Clusters
To create a K-means cluster with two clusters, simply type the following script:
kmeans = KMeans(n_clusters=2)
kmeans.fit(X)
Yes, it is just two lines of code. In the first line, you create a KMeans object and pass it 2 as value for n_clusters parameter. Next, you simply have to call the fit method on kmeans and pass the data that you want to cluster, which in this case is the X array that we created earlier.
Now let’s see what centroid values the algorithm generated for the final clusters. Type:
print(kmeans.cluster_centers_)
The output will be a two dimensional array of shape 2 x 2.
[[ 16.8 17. ]
[ 70.2 74.2]]
Here the first row contains values for the coordinates of the first centroid i.e. (16.8 , 17) and the second row contains values for the coordinates of the other centroid i.e. (70.2, 74.2). You can see that these values are similar to what we calculated manually for centroids c1 and c2 in the last section. In short, our algorithm works fine.
To see the labels for the data point, execute the following script.
print(kmeans.labels_)
The output is a one dimensional array of 10 elements corresponding to the clusters assigned to our 10 data points.
[0 0 0 0 0 1 1 1 1 1]
Here the first five points have been clustered together and the last five points have been clustered. Here 0 and 1 are merely used to represent cluster IDs and have no mathematical significance. If there were three clusters, the third cluster would have been represented by digit 2.
Let’s plot the data points again on the graph and visualize how the data has been clustered. This time we will plot the data along with their assigned label so that we can distinguish between the clusters. Execute the following script:
plt.scatter(X[:,0],X[:,1], c=kmeans.labels_, cmap='rainbow')
Here we are plotting the first column of the X array against the second column, however in this case we are also passing kmeans.labels_ as value for the c parameter that corresponds to labels. The cmap='rainbow' parameter is passed for choosing the color type for the different data points. The output graph should look like this:

As expected, the first five points on the bottom left have been clustered together (displayed with blue), while the remaining points on the top right have been clustered together (displayed with red).
Now let’s execute K-means algorithm with three clusters and see the output graph.
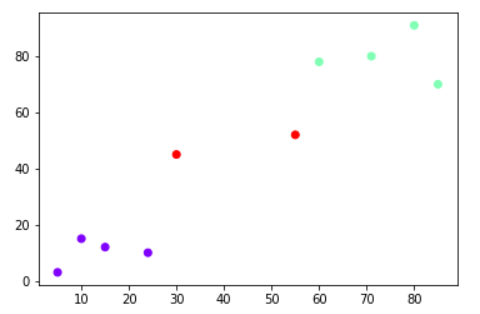
You can see that again the points that are close to each other have been clustered together.
Now let’s plot the points along with the centroid coordinates of each cluster to see how the centroid positions effects clustering. Again we will use three clusters to see the effect of centroids. Execute the following script to draw the graph:
plt.scatter(X[:,0], X[:,1], c=kmeans.labels_, cmap='rainbow')
plt.scatter(kmeans.cluster_centers_[:,0] ,kmeans.cluster_centers_[:,1], color='black')
Here in this case we are plotting the data points in rainbow colors while the centroids are in black. The output looks like this:
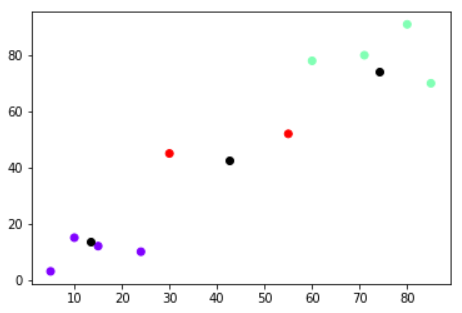
In case of three clusters, the two points in the middle (displayed in red) have distance closer to the centroid in the middle (displayed in black between the two reds), as compared to the centroids on the bottom left or top right. However if there were two clusters, there wouldn’t have been a centroid in the center, hence the red points would have to be clustered together with the points in the bottom left or top right clusters.
Resources
Want to learn more about Scikit-Learn and other useful machine learning algorithms? I’d recommend checking out some more detailed resources, like an online course:
While exploring blog posts like this is a great start, personally I tend to learn better with visuals, resources, and explanations from video courses like those linked above.
Conclusion
K-means clustering is a simple yet very effective unsupervised machine learning algorithm for data clustering. It clusters data based on the Euclidean distance between data points. K-means clustering algorithm has many uses for grouping text documents, images, videos, and much more.
Have you ever used K-means clustering in an application? If so, what for? Let us know in the comments!