Similarity to Probability — Part I: Visual Word Embedding for OCR Post Correction
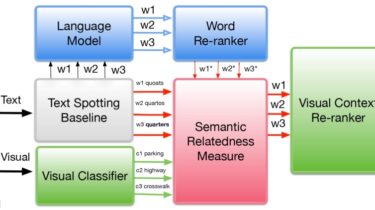
In this post, I will revisit in more detail our previous work that uses human-inspired likelihood revision or similarity to probability [Blok et al. 2003] to re-rank or score any word or text fragment based on the semantic relation to an external context. We will use the most popular Semantic Similarity pre-trained model (e.g., w2v, GloVe, fasttext, etc.) to compute these relations.