Learning from Guided Play: A Scheduled Hierarchical Approach for Improving Exploration in Adversarial Imitation Learning
Trevor Ablett*, Bryan Chan*, Jonathan Kelly (*equal contribution)
Poster at Neurips 2021 Deep Reinforcement Learning Workshop
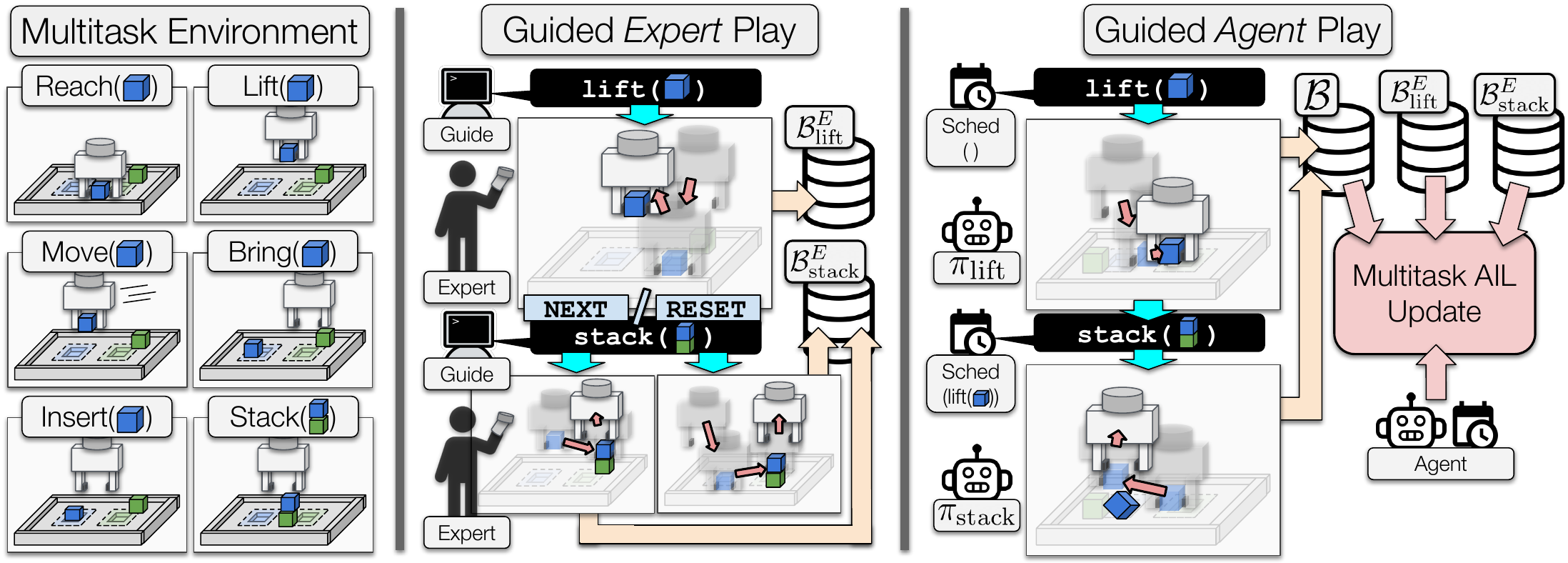
Adversarial Imitation Learning (AIL) is a technique for learning from demonstrations that helps remedy the distribution shift problem that occurs with Behavioural Cloning. Empirically, we found that for manipulation tasks, off-policy AIL can suffer from inefficient or stagnated learning. In this work, we resolve this by enforcing exploration of a set of easy-to-define auxiliary tasks, in addition to a main task.
This repository contains the source code for reproducing our results.
Setup
We recommend the readers set up a virtual environment (e.g. virtualenv, conda, pyenv, etc.). Please also ensure to use Python 3.7 as we