A recurrent unit that can run over 10 times faster than cuDNN LSTM
sru
SRU is a recurrent unit that can run over 10 times faster than cuDNN LSTM, without loss of accuracy tested on many tasks.
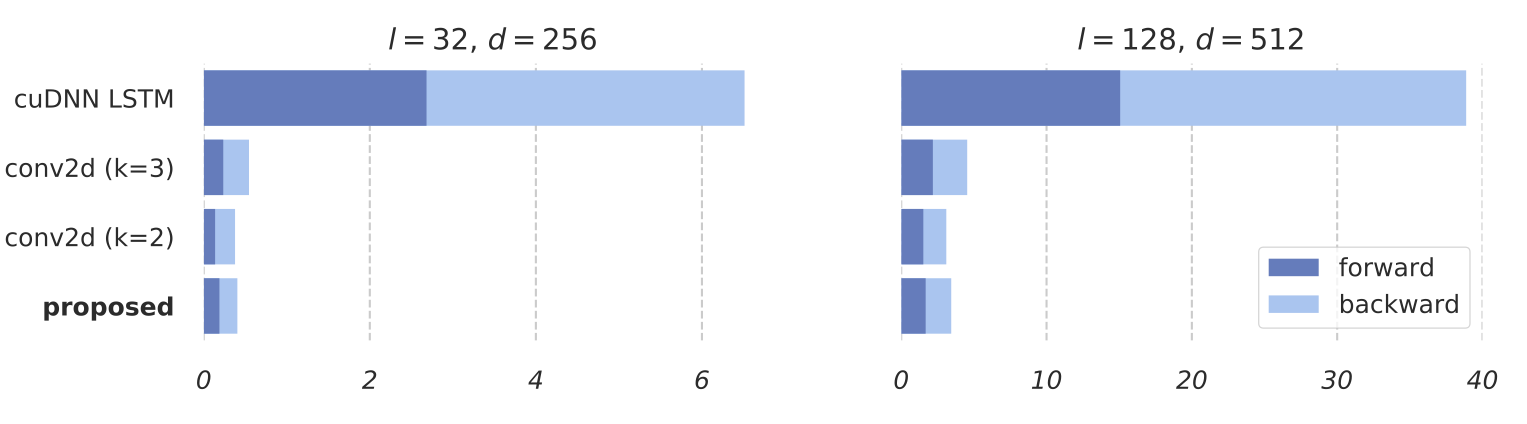
Average processing time of LSTM, conv2d and SRU, tested on GTX 1070
For example, the figure above presents the processing time of a single mini-batch of 32 samples. SRU achieves 10 to 16 times speed-up compared to LSTM, and operates as fast as (or faster than) word-level convolution using conv2d.
Reference:
Simple Recurrent Units for Highly Parallelizable Recurrence [paper]
@inproceedings{lei2018sru,
title={Simple Recurrent Units for Highly Parallelizable Recurrence},
author={Tao Lei and Yu Zhang and Sida I. Wang and Hui Dai and Yoav Artzi},
booktitle={Empirical Methods in Natural Language Processing (EMNLP)},
year={2018}
}
When Attention Meets Fast Recurrence: Training Language