Learning What To Do by Simulating the Past
Learning What To Do by Simulating the Past
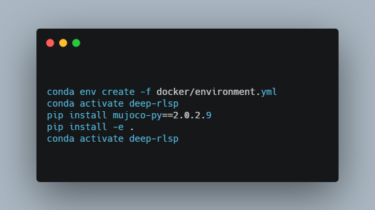
This repository contains code that implements the Deep Reward Learning by Simulating the Past (Deep RSLP) algorithm introduced in the paper “Learning What To Do by Simulating the Past”. This code is provided as is, and will not be maintained. Here we describe how to reproduce the experimental results reported in the paper. You can find video of policies trained with Deep RLSP here.
Citation
David Lindner, Rohin Shah, Pieter Abbeel, Anca Dragan. Learning What To Do by Simulating the Past. In International Conference on Learning Representations (ICLR), 2021.
@inproceedings{lindner2021learning,
title={Learning What To Do by Simulating the Past},
author={Lindner, David and Shah, Rohin and Abbeel, Pieter and Dragan, Anca},
booktitle={International Conference on Learning Representations (ICLR)},
year={2021},
}