Data pipeline architecture for onboarding public datasets to Datasets for Google Cloud
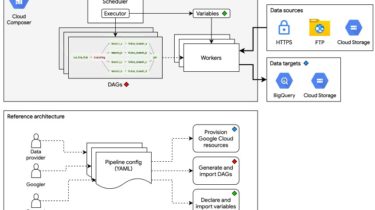
Public Datasets Pipelines
Cloud-native, data pipeline architecture for onboarding public datasets to Datasets for Google Cloud.
We use Pipenv to make environment setup more deterministic and uniform across different machines.
If you haven’t done so, install Pipenv using the instructions found here. Now with Pipenv installed, run the following command:
pipenv install --ignore-pipfile --dev
This uses the Pipfile.lock found in the project root and installs all the development dependencies.
Finally, initialize the Airflow database:
pipenv run airflow initdb
Configuring, generating, and deploying data pipelines in a programmatic, standardized, and scalable way is the main purpose of this repository.
Follow the steps below to build a data pipeline for your dataset:
1. Create a folder hierarchy for your pipeline
mkdir -p datasets/DATASET/PIPELINE
[example]
datasets/covid19_tracking/national_testing_and_outcomes