A Framework for Any-to-Any Voice Conversion with Self-Supervised Pretrained Representations
S2VC
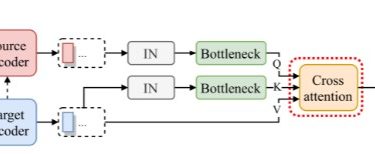
Here is the implementation of our paper S2VC: A Framework for Any-to-Any Voice Conversion with Self-Supervised Pretrained Representations. In this paper, we proposed S2VC which utilizes Self-Supervised pretrained representation to provide the latent phonetic structure of the utterance from the source speaker and the spectral features of the utterance from the target speaker.
The following is the overall model architecture.
For the audio samples, please refer to our demo page.
Usage
You can download the pretrained model as well as the vocoder following the link under Releases section on the sidebar.
The whole project was developed using Python 3.8, torch 1.7.1, and the pretrained model, as well as the vocoder, were turned to TorchScript, so it’s not guaranteed to be backward compatible.
You can install the