PyTorch implementation and pretrained models for XCiT models
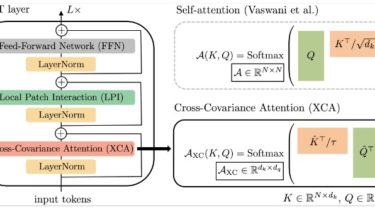
Cross-Covariance Image Transformer (XCiT)
PyTorch implementation and pretrained models for XCiT models. See XCiT: Cross-Covariance Image Transformer
Linear complexity in time and memory
Our XCiT models has a linear complexity w.r.t number of patches/tokens:
 |
 |
|---|---|
| Peak Memory (inference) | Millisecond/Image (Inference) |
Scaling to high resolution inputs
XCiT can scale to high resolution inputs both due to cheaper compute requirement as well as better adaptability to higher resolution at test time (see Figure 3 in the paper)
Detection and Instance Segmentation for Ultra high resolution images (6000×4000)

XCiT+DINO: High Res. Self-Attention Visualization :t-rex:
Our XCiT models with self-supervised training using DINO can obtain high resolution attention maps.