A Stack of Feed-Forward Layers Does Surprisingly Well on ImageNet
Do You Even Need Attention?
A Stack of Feed-Forward Layers Does Surprisingly Well on ImageNet
TL;DR
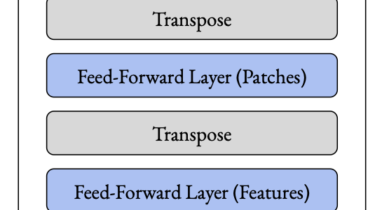
We replace the attention layer in a vision transformer with a feed-forward layer and find that it still works quite well on ImageNet.
Abstract
The strong performance of vision transformers on image classification and other vision tasks is often attributed to the design of their multi-head attention layers. However, the extent to which attention is responsible for this strong performance remains unclear. In this short report, we ask: is the attention layer even necessary? Specifically, we replace the attention layer in a vision transformer with a feed-forward layer applied over the patch dimension. The resulting architecture is simply a series of feed-forward layers applied over the patch and