TensorFlow implementation of Barlow Twins
Barlow-Twins-TF
This repository iimplements Barlow Twins (Barlow Twins: Self-Supervised Learning via Redundancy Reduction) in TensorFlow and demonstrates it on the CIFAR10 dataset.
Summary:
With a ResNet20 as a trunk and a 3-layer MLP (each layer containing 2048 units) and 100 epochs of pre-training, this training notebook can give 62.61% accuracy on the CIFAR10 test set. The pre-training total takes ~23 minutes on a single Tesla V100. There are minor differences from the original implementation. However, the original loss function and the other minor details like having a big enough projection dimension have been maintained.
For details on Barlow Twins, I suggest reading the original paper, it’s really well-written.
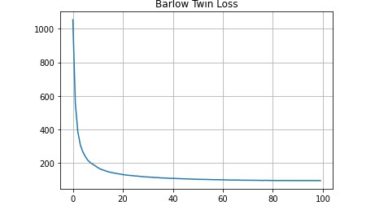
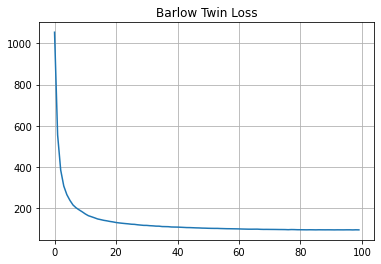
Loss progress during pre-training
Other notes
- Pre-trained model is available here.