AOT-GAN for High-Resolution Image Inpainting
AOT-GAN-for-Inpainting
AOT-GAN: Aggregated Contextual Transformations for High-Resolution Image Inpainting
Yanhong Zeng, Jianlong Fu, Hongyang Chao, and Baining Guo.
AOT-GAN: Aggregated Contextual Transformations for High-Resolution Image Inpainting
Yanhong Zeng, Jianlong Fu, Hongyang Chao, and Baining Guo.
Citation
If any part of our paper and code is helpful to your work,
please generously cite and star us :kissing_heart: :kissing_heart: :kissing_heart: !
@inproceedings{yan2021agg,
author = {Zeng, Yanhong and Fu, Jianlong and Chao, Hongyang and Guo, Baining},
title = {Aggregated Contextual Transformations for High-Resolution Image Inpainting},
booktitle = {Arxiv},
pages={-},
year = {2020}
}
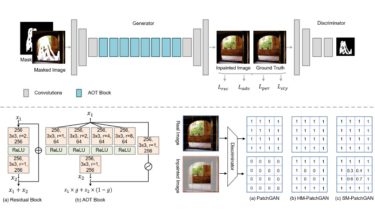
Introduction
Despite some promising results, it remains challenging for existing image inpainting approaches to fill in large missing regions in high resolution images (e.g., 512×512). We analyze that the difficulties mainly drive from simultaneously inferring missing contents and synthesizing