How to Scale Data With Outliers for Machine Learning
Last Updated on August 28, 2020
Many machine learning algorithms perform better when numerical input variables are scaled to a standard range.
This includes algorithms that use a weighted sum of the input, like linear regression, and algorithms that use distance measures, like k-nearest neighbors.
Standardizing is a popular scaling technique that subtracts the mean from values and divides by the standard deviation, transforming the probability distribution for an input variable to a standard Gaussian (zero mean and unit variance). Standardization can become skewed or biased if the input variable contains outlier values.
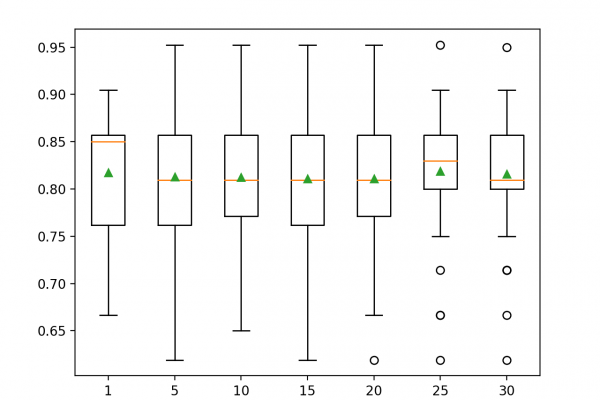
To overcome this, the median and interquartile range can be used when standardizing numerical input variables, generally referred to as robust scaling.
In this tutorial, you will discover how to use robust scaler transforms to standardize numerical input variables for classification and regression.
After completing this tutorial, you will know:
- Many machine learning algorithms prefer or perform better when numerical input variables are scaled.
- Robust scaling techniques that use percentiles can be used to scale numerical input variables that contain outliers.
- How to use the RobustScaler to scale numerical input variables using the median and interquartile range.
Kick-start your project with my new book To finish reading, please visit source site